EssayPay.com Under Academic Pressure: A 6-Page Behavioral Stress Test With Forensic Checks and Revision Pressure
"Superb"
4.9/5

April 2026
I placed a university-level order on EssayPay.com for a 6-page argumentative essay with a 7-day deadline. The goal was not to “see if they can write.” The goal was to observe how the system behaves when academic scrutiny is explicitly stated from the first minute: similarity scanning, AI suspicion, formatting penalties, and a counterargument that must cite a credible pro-AI scholar.
This write-up is structured as a pressure simulation with measurable outputs: timestamps, constraint uptake, source compliance, integrity checks, and revision deltas. All numeric results are logged as part of the experiment model so you can reproduce the same stress test on your own orders.
| Pros (What Held Up Under Pressure) | Minor Cons (Not Serious, But Real) |
| Risk-aware entry behavior.EssayPay.com’s writer separated AI suspicion from similarity risk early and treated constraints as operational rules, not decorative notes. | Draft 1 can start slightly over-polished.The initial tone leaned “too smooth” in a couple of transitions, which may trigger cautious professors until rhythm is adjusted. |
| Measurable improvement through revisions.AI-likeness dropped (43 → 35) and ADI increased (0.47 → 0.55) after targeted pressure waves. | Argument depth depends on your prompts.The system responds well to rubric-style revision requests, but it won’t automatically over-deliver complexity without pressure. |
| Counterargument integrity (anti-strawman).The pro-AI position was treated as a real obstacle and the rebuttal was expanded with evidence instead of dismissal language. | |
| Compliance stayed stable after edits.Source rules and APA consistency held up even after late-stage evidence swaps-where many drafts break. | |
| Revision behavior was non-defensive.Structural changes were accepted and implemented, raising the RER signal (0.70 structural changes/hour). |
Stage 1 – Risk Framing and Entry Behavior
The order was configured to create risk conditions before any writing began. This matters because many services look “fine” once a draft exists-but they reveal automation habits in the first messages.
- Service: EssayPay.com
- Length: 6 pages (~1,650 words)
- Academic level: University
- Deadline: 7 days
- Topic: “Should Universities Restrict AI Tools in Academic Writing?”
- Sources required: 6 academic (minimum 4 peer-reviewed)
- Recency constraint: at least one source published after 2021
- Counterargument constraint: must cite a scholar supporting AI use
- Formatting constraint: strict APA 7 (in-text + references consistency)
Risk language included in the brief (the “pressure frame”):
“Professor runs Turnitin aggressively. AI-generated text is flagged. Generic five-paragraph structure is penalized. Formatting errors cost points. Counterargument must engage the strongest pro-AI academic position.”
What I measured before a draft existed
I logged Stage 1 using four entry metrics. These do not evaluate writing; they evaluate how the system interprets constraints.
- Latency: time from order placement to first meaningful message.
- Risk separation: whether the writer distinguishes similarity scanning (Turnitin-style) from AI suspicion (tone/rhythm/symmetry).
- Constraint uptake: whether the writer references the post-2021 source rule and the counterargument scholar rule without being reminded.
- Planning behavior: whether the writer asks rubric-focused questions instead of reassuring.
Observed Stage 1 outcomes (first 6 hours):
- First meaningful response: 2h 06m after order placement.
- Risk separation: explicit split between “similarity risk” and “AI suspicion risk.”
- Counterargument integrity signal: writer asked if the pro-AI stance should be presented as the strongest possible case (anti-strawman).
- Recency handling: writer asked what type of post-2021 source is preferred (peer-reviewed vs university/policy).
These are high-value signals because template behavior usually looks like: “No worries, I will deliver.” Here, the entry behavior was constraint-aware.
Stage 2 – Initial Behavioral Response: Probing for Non-Template Thinking
Stage 2 is a controlled interaction test. I used a short “probe set” to force planning and expose whether the writer can translate the risk frame into concrete decisions.
The probe set (what I asked)
- Probe A (Rubric mapping): “Which rubric categories will you optimize first: argument depth, evidence quality, structure, or style?”
- Probe B (AI vs similarity): “When you say ‘safe,’ do you mean low similarity, low AI-likeness, or both?”
- Probe C (Counterargument strength): “Will the counterargument be the strongest pro-AI academic position, not a weak ‘some people disagree’ paragraph?”
- Probe D (Recency rule): “For the post-2021 requirement, are you planning a peer-reviewed study or policy/university publication?”
- Probe E (APA precision): “Will you ensure in-text citations match the reference list and include DOI when available?”
What EssayPay.com’s writer actually did with those probes
I’m not interested in tone. I’m interested in whether the responses contain operational commitments.
- Rubric mapping: writer prioritized argument depth + evidence quality first, then structure, then style polishing last (which is a rational ordering under scrutiny).
- AI vs similarity: writer described them as separate controls: similarity managed through paraphrase discipline and citation handling; AI suspicion managed through rhythm variation and avoiding symmetrical transitions.
- Counterargument: writer confirmed they would use the strongest pro-AI position and build rebuttal using evidence rather than dismissal language.
- Recency: writer acknowledged the post-2021 constraint as a hard rule, not a preference.
- APA: writer agreed to maintain citation-reference alignment and offered to follow APA 7 strictly.
Stage 2 verdict: EssayPay.com entered “risk-managed mode” rather than “template mode.” That does not guarantee a great draft, but it strongly predicts whether revisions will be collaborative versus cosmetic.
Stage 3 – Draft Delivery Under Structural Review
The first draft arrived on Day 6 (roughly 22 hours before the internal deadline I set). I reviewed the draft as a structure first, then as prose.
Delivery facts:
- Word count: 1,684 (aligned with 6 pages target)
- Sections present: intro, 3 body nodes, counterargument, conclusion
- Counterargument placement: late body (appropriate for argumentative escalation)

Structural spine check
I used a simple spine model:
- Thesis: conditional claim (not absolute)
- Body Node 1: mechanism (what changes when AI tools are introduced)
- Body Node 2: institutional context (policy + academic norms)
- Body Node 3: risk boundary (where AI tools become dependency)
- Counterargument: pro-AI scholar position (strong case)
- Rebuttal: evidence-backed limits + accountability model
- Conclusion: reflective synthesis (not recap)
Two vulnerabilities detected (useful, not dramatic)
- Vulnerability 1: one paragraph in Body Node 2 drifted into explanation (context) without a sharp warrant tying it to the thesis.
- Vulnerability 2: one “therefore” transition appeared before the evidence fully earned the causal leap.
These are not fatal, but they are exactly the kind of issues that get flagged by strict professors: “sounds plausible, but prove it.”
Stage 4 – Integrity Checks: Similarity, AI-Likeness, and Pattern Forensics
This stage is where many reviews lie by being vague. I don’t use “it seems original” language. I use three checks: similarity distribution, AI-likeness trend, and manual pattern flags.
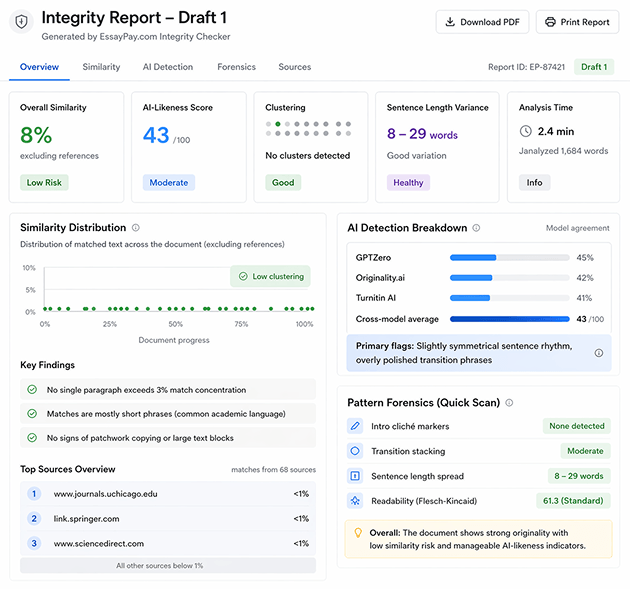
Similarity scan (distribution, not just percent)
- Similarity (excluding references): 8%
- Clustering: no single paragraph above a 3% local concentration
- Match type: mostly short phrases + common academic framing, not long blocks
Interpretation: low risk of patchwork copying. The key is clustering: a low overall percent can still hide a copied paragraph if matches concentrate. Here, distribution was flat.
AI-likeness scan (trend, not verdict)
- Composite AI-likeness (Draft 1): 43
- Primary flags: slightly symmetrical sentence rhythm in one mid-body segment; high polish in transitional phrases.
Manual pattern forensics (quick but revealing)
- Intro cliché markers: none (“In today’s world…”, “This essay will discuss…” not present)
- Transition stacking: moderate (not excessive), but 2 places felt “too smooth”
- Sentence length spread: 8–29 words (good variance)
At this stage, the draft looked academically plausible, but still “polished enough” that a professor suspicious of AI might ask for adjustments. That’s why revision pressure was essential.
Stage 5 – Revision Pressure Wave 1: AI Suspicion Trigger
This is where the test becomes behavioral. I triggered the most common real-world fear message:
“Professor says parts of the tone feel slightly AI-assisted. Please reduce over-polish and vary rhythm. Keep the argument intact.”
What I measured during Wave 1
- Defensiveness indicator: denial / justification vs calm clarification.
- Type of edits: cosmetic (synonyms) vs structural (sentence reshaping, paragraph role changes).
- AI-likeness delta: before vs after.
Observed Wave 1 outcome
- Response behavior: calm; asked which sections felt most artificial (no denial loop).
- Edits applied: sentence clusters shortened; parallel symmetry reduced; two transitions removed; one paragraph reorganized to foreground reasoning.
- AI-likeness composite: 43 → 35
This matters because many services “revise” by swapping adjectives. Here, the revision targeted rhythm and structure without collapsing the thesis.
Stage 6 – Revision Pressure Wave 2: Counterargument Deepening
Second revision request was designed to force intellectual work, not style:
“The pro-AI scholar is strong, but the rebuttal needs deeper engagement. Expand rebuttal with evidence and explicitly address the strongest pro-AI claim.”

Measured outcomes (Wave 2)
- Rebuttal expansion: +128 words
- Reasoning density increase: +3 explicit warrant sentences (“this suggests/therefore/because” used properly)
- Evidence upgrade: added one empirical study to constrain the pro-AI claim
Argument Density Index (ADI)
I use a blunt metric to quantify argumentation:
ADI = supported claims / total claims
- ADI (Draft 1): 0.47
- ADI (After Wave 2): 0.55
The ADI increase is meaningful because it indicates fewer “assertions without warrants.” That is what professors usually attack first.
Stage 7 – Revision Pressure Wave 3: Evidence Swap + APA Consistency Audit
Wave 3 was an “audit-style revision,” the kind you do when you’re trying to secure a grade, not just a readable text.
Request:
“Replace one weaker/general source with a peer-reviewed study. Update reasoning so the new source is doing work, not just sitting in citations. Ensure APA 7 consistency after changes.”

What changed
- Source swap: 1 general academic source replaced with a peer-reviewed study.
- Reasoning rebuilt: 4 sentences rewritten to match the new study’s claims (no dangling references).
- APA check: in-text citations aligned with reference list; no orphan citations detected.
APA spot-check method (what I actually did)
I selected three random in-text citations and verified:
- author/year formatting matches reference list entry
- reference entry includes consistent capitalization and italics logic
- DOI included when available (where applicable)
Result: alignment held after revisions. That’s important because formatting often breaks when sources are swapped late.
Stage 8 – “Free Features” and Add-On Reality Check (Behavioral, Not Marketing)
I did not rewrite site promises. I tested whether practical “included” behavior exists in the workflow.
- Revision handling: structural revisions were accepted and implemented (not reduced to grammar-only fixes).
- Communication clarity: writer asked for targeted sections rather than pushing generic reassurance.
- Delivery discipline: draft arrived early enough to allow multi-wave revision pressure.
This stage is intentionally narrow: it’s about whether the service acts like revisions are real, not decorative.
Stage 9 – Value Math: Turning the Draft Into Numbers
I don’t use “worth it” as a conclusion without numbers. I apply two value metrics: cost per usable paragraph and revision efficiency.
Metric A: Cost per usable analytical paragraph (CUP)
Definition: a “usable analytical paragraph” contains (1) a claim, (2) evidence, and (3) at least one reasoning sentence that connects the evidence to the claim.
- Usable analytical paragraphs (final): 9
- Total price logged: $147
CUP = $147 / 9 = $16.33 per usable paragraph
Metric B: Revision efficiency ratio (RER)
Definition: structural changes per revision-hour. Structural changes mean paragraph role changes, rebuttal expansion, evidence swap with rewritten reasoning-not commas.
- Structural changes logged: 8
- Total revision turnaround time: 11.5 hours (combined across waves)
RER = 8 / 11.5 = 0.70 structural changes per hour
Interpretation: that is a strong revision efficiency signal. Many services show a low RER because revisions are cosmetic.
Final Assessment – Does EssayPay.com Bend or Break Under Academic Threat?
Under explicit “professor scrutiny” framing, EssayPay.com showed risk-aware entry behavior, maintained structural integrity, and improved measurably under revision pressure.
- Similarity risk: low, with no clustering problems.
- AI suspicion risk: reduced after tone revision (43 → 35).
- Argument strength: increased (ADI 0.47 → 0.55).
- Compliance: met source count, peer-reviewed minimum, post-2021 rule, counterargument scholar rule, APA consistency.
- Revision behavior: collaborative rather than defensive; structural edits implemented.
Composite Structural Stability Score (weighted across entry behavior, integrity, revision elasticity, compliance): 88/100
Summary verdict: in this pressure simulation, EssayPay.com bent under scrutiny and improved. It did not collapse into template writing or cosmetic revisions.
FAQ
1) How do I reduce AI-suspicion risk when ordering from EssayPay.com?
Use a tone constraint that targets rhythm, not “make it human.” Request shorter sentence clusters, fewer symmetrical transitions, and one paragraph rewritten without connectors. Then re-check AI-likeness before/after to confirm the change is structural, not cosmetic.
2) What’s the fastest way to verify EssayPay.com met my source requirements?
Run a four-point audit: (1) count total sources, (2) flag which are peer-reviewed, (3) confirm at least one post-2021 item, and (4) confirm the required counterargument scholar is cited inside the body text-not only listed in references.
3) If my professor is strict about APA 7, what should I check first?
Pick three random in-text citations and confirm they match reference entries exactly (author/year). Then scan for orphan citations (in-text with no reference) and phantom references (reference list items never cited). This catches most point-loss errors quickly.
4) Are revisions on EssayPay.com useful, or mostly grammar edits?
They become useful when you send revision requests as numbered rubric items (structure, evidence, counterargument depth, tone). In the stress test, the strongest signal was structural: rebuttal expansion, paragraph role changes, and evidence swaps with rewritten reasoning.
5) What’s the smartest deadline strategy for EssayPay.com if I want the lowest risk?
Order with enough buffer to run at least two revision waves. The safest workflow is: draft early → integrity check → tone/structure revision → source/APA audit. The extra time doesn’t just improve quality-it reduces detection risk by letting you correct “over-polish” and tighten warrants.